from fairdatanow import DataViewer
import matplotlib.pyplot as plt
import os
import numpy as npHow to make sense of thousands of data files?
Answer: import fairdatanow
Here is the thing. Our colleagues in the Falnama project team worked hard and so far uploaded several thousands of data files to our Nextcloud self-hosted open source cloud storage. Many of these files are formatted and stored in such a way that it is difficult or impossible to explore them. It is our task as developers in the team to build and apply data processing algorithms in order to visualize our data in such a way that we can actually start to ask interdisciplinary questions and get answers!
configuration = {
'url': "https://laboppad.nl/falnama-project",
'user': os.getenv('NC_AUTH_USER'),
'password': os.getenv('NC_AUTH_PASS')
}
filters = {'columns': ['path', 'size', 'modified', 'ext'],
'extensions': [],
'search': '',
'show_directories': False,
'show_filters': False,
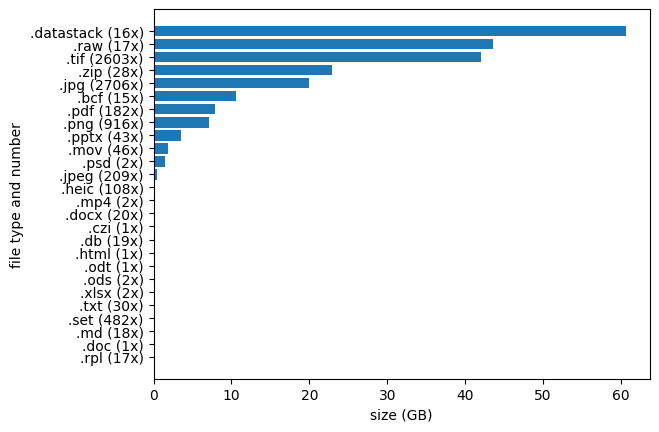
'use_regex': False}dv = DataViewer(configuration, **filters)dvTo get a first idea about the types of data files we are up against, let’s see how many files we have for each type, and what their size is.
Falnama-project - Total size: 222.92 GB, Total number of files: 7487